

OpenAI's gpt-oss Proves Healthcare AI Still Needs Human Babysitters
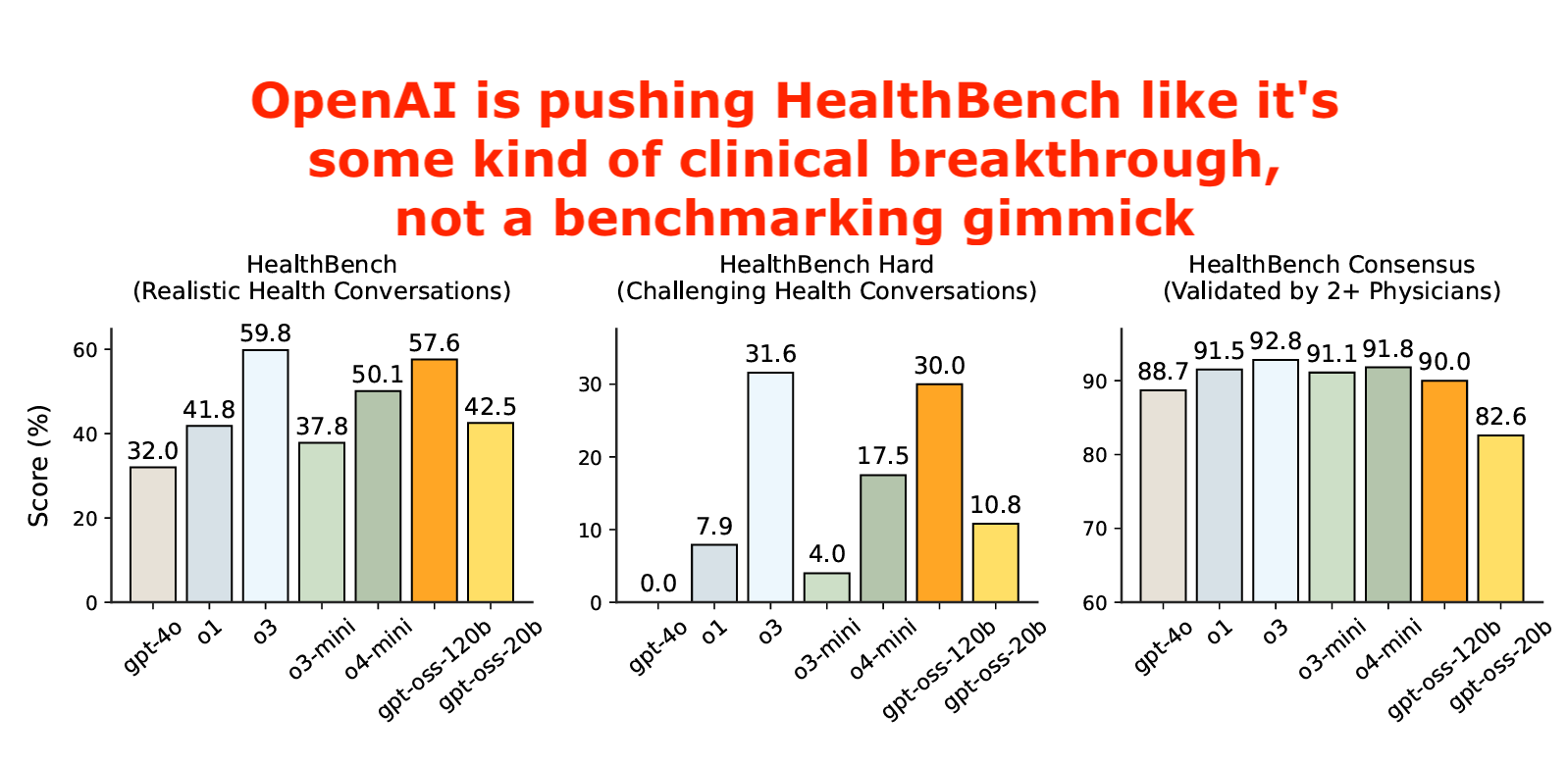
OpenAI is pushing HealthBench in every model release like it's a clinical breakthrough, when it's really just a man-made benchmarking gimmick.

Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
Yesterday, August 5, OpenAI has released its first open-weight language models since GPT-2, called gpt-oss. (I had a nice little video message about that 😉.) This marks a pivotal shift in its stance toward the open-source ecosystem and also a weak effort to compete with already established open-source models such as Meta’s Llama 4, DeepSeek V3, Qwen 3, Kimi K2, GLM 4.5, and Hunyuan-A13B-Instruct. Many of those models are Chinese, which makes me wonder how much politics and good ol’ Trump ass-kissing are now part of AI development. 🙄
The two models—gpt-oss-20B (3.6B active parameters and 21B total) and gpt-oss-120B (5.1B active)—are so-called Mixture of Experts (MoE) models. They are released under the Apache 2.0 license. That is the nicest, the most beautiful license. I’m not kidding, folks. This enables broad commercial use, distillation, and modification. In a way, this might just be the best part of the entire release. 😄
But first, a quick announcement. On September 11, 2025, I’ll be moderating the panel “GenAI in Healthcare: A Conversation with Foundation Model Builders” at the Prax AI x Healthcare Summit in NYC. (Apparently, I’ve been getting invited to a lot of things lately. I’ll tell you more in future posts. 😉)
I don’t say this often, but the agenda for this conference actually looks really strong, especially if you’re in healthcare AI.
Also, if you’d like to become a Founding Member of the AI Health Uncut community, you can join through this link. You’ll be making a real impact, helping me continue to challenge the system and push for better outcomes in healthcare through AI, technology, policy, and beyond.
Alright, back to gpt-oss…
https://youtube.com/shorts/Dj46qyuN6-k
TL;DR:
1. Strategic impact of gpt-oss.
2. Technical notes and parameters of gpt-oss.
3. Technical limitations of gpt-oss.
4. Can gpt-oss compete with the dominance of Chinese open source models?
5. Beating benchmarks ain’t hard when you train on them
6. Is OpenAI giving up on fine tuning?
7. Data is king – again (the future in the current “lazy vibe coding” reality belongs to the dataset, not the algorithm)
8. Will GPT-5 be any better for healthcare?
9. Conclusion: Is gpt-oss a success or failure? My 5 Renminbi. 😉
1. Strategic impact of gpt-oss.
Break from past secrecy: This is OpenAI’s most open release to date, with access to raw weights, prompt formats, tool use behaviors, and reasoning strategies.
Competitive pressure: gpt-oss-120B achieves near parity with OpenAI’s proprietary o4-mini, but is ~10x cheaper to run. (You can run it on your phone. At least, that’s what Sam Altman claims. 🤷♂️) This aggressively undercuts OpenAI’s own API offerings and rivals like Claude Haiku and Gemini Flash.
Enterprise targeting: While marketed as “open source,” the release is clearly aimed at enterprise adoption, not hardcore open-source purists.
2. Technical notes and parameters of gpt-oss.
Sparsity trend: Models follow current MoE architecture norms with high sparsity. Quantized to 4-bit (MXFP4), optimized for GPUs like A100/H100.
Tool use + hallucinations: Models were trained with tools in the loop, leading to ‘occasional’ hallucinated tool calls. A signal of the complexity of aligning training and inference time tools.
Safety + finetuning: OpenAI claims the model is finetunable, but has released research aimed at preventing “safety finetuning removal,” a rather controversial feature. 🤔
Note: Mixture of Experts (MoE) is like having a team of specialists instead of one generalist. Imagine you want advice on cooking, car repair, and gardening. You could ask a single expert who knows a little about everything, or you could consult three specialists who each know a lot about one topic. An MoE model works the same way. It has many “expert” sub-models, each trained on different patterns or skills. When you give the model a question, a tiny router network quickly decides which few experts are best suited to answer. Only those experts get to work, which saves time and memory compared to firing up every part of the model. The result is faster and cheaper inference without sacrificing the quality you’d get from a large all-around model.
3. Technical limitations of gpt-oss.
No base models or training data: This limits scientific reproducibility and real openness for the research community.
Naming ambiguity: “gpt-oss” blurs the definition of open source. It’s a marketing-friendly name, not community-driven.
Not multimodal: Text-only. OpenAI encourages those needing multimodal capabilities to stick with its API products.
4. Can gpt-oss compete with the dominance of Chinese open source models?
China’s dominance in open models: China leads with massive, competitive MoE models (e.g. DeepSeek V3, Kimi K2, GLM 4.5). The U.S. had been falling behind.
Western catch-up: This release signals a potential reversal of the trend, if momentum continues. But future progress depends on releasing dense base models and full training data.
Risks & lawsuits: American labs face greater legal exposure, especially around copyright, making fully open releases difficult compared to Chinese firms.
So can gpt-oss compete with the Chinese?
