

Panda vs. Gibbon, MD: 100% Accuracy, My A**. Looking at You, OpenEvidence.
10 years later, the same trivial noise injection still fools medical AI models and the cost is no longer a meme but a patient.

Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
So we all remember OpenEvidence’s bold claim of 100% accuracy on USMLE — a multiple-choice benchmark and a variant of MedQA, the large medical question-answering dataset — made just a couple of weeks ago. Aside from the fact that answering USMLE questions is a far cry from operating in a real-life clinical setting, that claim was, in my opinion, a real insult to the scientific community. From freshman year Stats 101, we all know that constructing a statistical test with 100% predictive power would never fly with any professor. 😉
But in all seriousness, the implications of such claims go far beyond academic nitpicking. That’s what I explain in this article.

But first, a quick reminder. I was hired as a moderator (well, let’s be honest, the instigator 😉) for the panel “GenAI in Healthcare: A Conversation with Foundation Model Builders” at the Prax AI x Healthcare Summit in NYC on September 11, 2025. The agenda looks really strong, especially if you’re in healthcare AI. My panel features some distinguished guests, including an executive from OpenAI. Should be a lot of fun.
Get $100 off the ticket price when you become a paid subscriber to AI Health Uncut.
I’ve already asked my dear founding members, an elite group of 17, for their advice on the most provocative topics and questions to bring to the panel. And boy, did they deliver.
Early next week, just before the conference, I’ll be asking my paid subscribers to help pick the best questions (maybe through a poll?). I’ll have dozens to choose from, but realistically, for a 30-minute panel (plus 15 minutes of Q&A), I’ll only be able to ask 5–6 max. So your input will really matter. Thank you in advance for participating in the poll.
Alright, back to OpenEvidence and its oh-so-perfect fairytale of being flawless in healthcare. 😊
TL;DR:
1. OpenEvidence claims “perfect” USMLE score. Trust them? 🙄
2. Two weeks later: OpenEvidence is asking VCs for cash. Coincidence? 😉
3. I put OpenEvidence to a real test. It flopped on 11 NEJM questions. 🙄
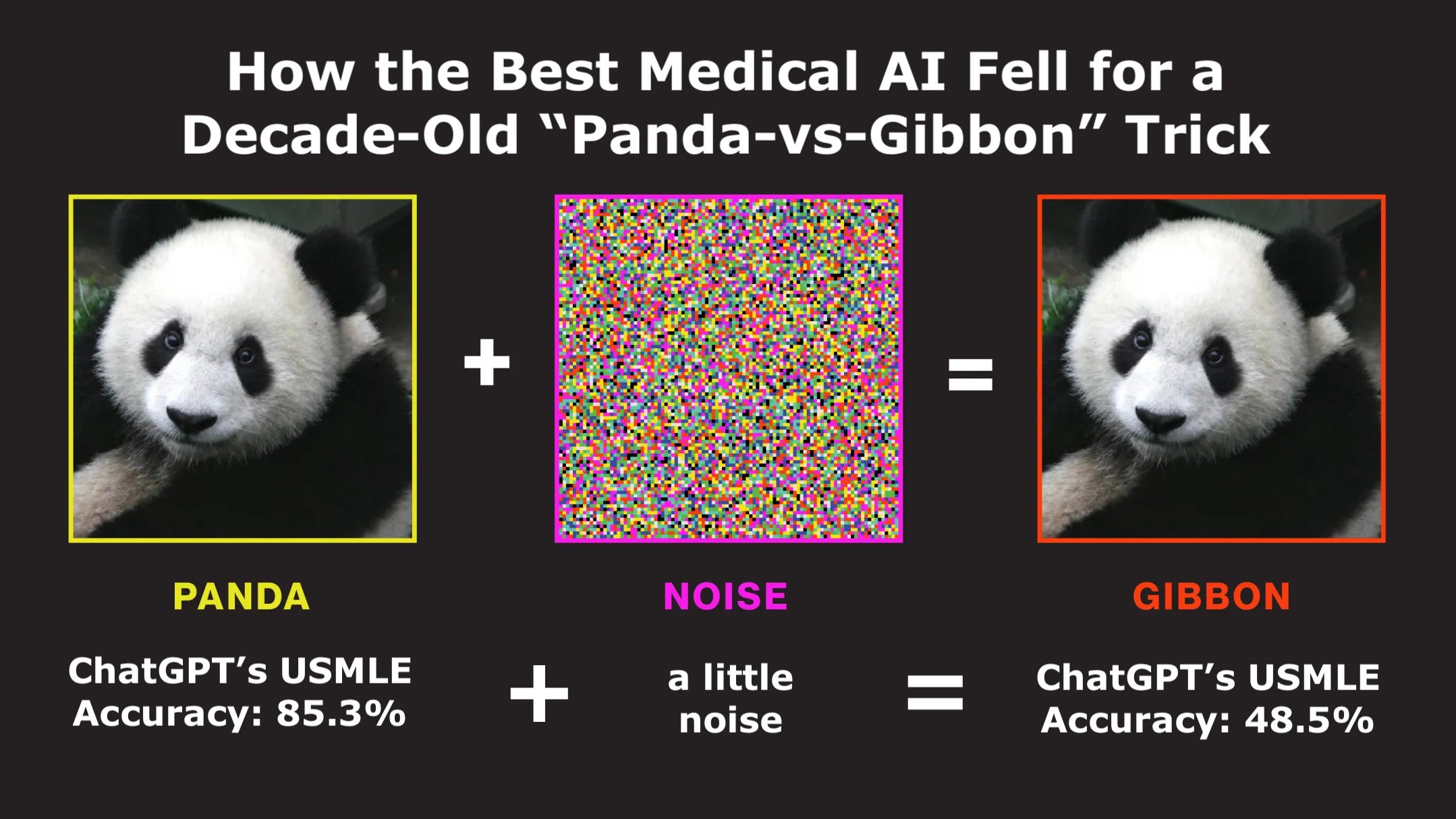
4. The original Panda-Gibbon story
5. Panda vs Gibbon in healthcare—Stanford’s clever trap shows ChatGPT ain’t that smart
6. Medical AI benchmarks are gamed
7. Hype fuels danger: WSJ op-ed tells patients to use chatbots 🤯
8. Conclusion: Be Smart. Separate Signal From Noise. Patient’s lives are on the line.
