

The Cough That Broke 12 LLMs
After 5 months, the same medical vignette is back, and 12 out of 13 LLMs we tested still can't solve it. So why are we calling this a success? You have to read the whole study to find out. 😉


Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
Before I introduce my co-author for this study and, let’s be honest, the man who did all the work, I want to remind my subscribers of my mission: to serve patients, clinicians, and the broader medical community with truthful, brutally honest information, especially when it comes to AI models in healthcare, AI products in healthcare, and AI healthcare companies.
My evidence-based investigations often anger the companies I write about. They come with blowback, including threats.
I’m not going to be intimidated. I’m going to stay true to my mission.
But I’m also not going to pretend I’m running a newsroom. This is a one-man operation, and these investigations take time and resources.
That’s why I’m genuinely grateful for every paid subscriber, and I’m especially grateful to my founding members. All 19 of you. Thank you! 🙏
If you’d like to support my mission and to become a Founding Member of the AI Health Uncut community, you can join through this link. You’ll be making a real impact, helping me continue to challenge the system and push for better outcomes in healthcare through AI, technology, policy, and beyond.
And a quick announcement.

I will be speaking at the Digital Health and AI Innovation Summit (DHAI) 2026 in Boston on June 8-9. Register here. I’ll be talking about my newly developed methodology for measuring VC skill in picking “generational companies.” It’s based on a unique dataset of around 200 publicly traded health tech companies and around 2,000 investment firms and individuals that invested in them. It’s a massive dataset I tediously built over the past several months. And unlike the Forbes annual ranking, I’m using performance metrics, not some subjective “perception of greatness.” 😉 I’ll explain more about this dataset in future posts. I also plan to offer free access to it for my Founding Members.
Alright. Back to the story of why LLMs suck at medical reasoning…
Let me introduce Dr. Peter Farag, who is the key researcher of this study.

Dr. Peter S. Farag is a board-certified internal medicine physician and Principal Investigator of clinical trials. He has a strong interest in optimization of system processes and practices by the principle that, “True progress is born of a courage that disrupts the present, not for the sake of change, but to forge the better way we know is possible”. During residency, he contributed to the optimization of asthma care by collaborating with the Chair of the Canadian Respirology Guidelines Committee and writing the backend logic for an EMR-integrated, algorithmic decision-support tool. He subsequently received the Top Quality Improvement Paper award at an international conference for a self-initiated project examining handover quality in downtown Toronto hospital. Since moving to the U.S. to focus on clinical research, he has conducted over 3300 in-person visits across 42 Phase I-IV studies. From August to October 2025, his site was ranked first globally for Query Resolution and Data Entry efficiency in an international obesity trial. With a growing desire to address systemic inefficiencies in the field, Dr. Farag serves as his company’s medical consultant for evaluation and development of clinical AI tools. Outside of work, Dr. Farag enjoys playing soccer, vibe-coding, and designing medical prompts to challenge LLMs.

TL;DR:
1. NEJM Challenge Cases Tested on 4 LLMs
2. When a Simple Cough Becomes a Hallucination Factory
3. March 2026. Same Cough, But With a Couple MAD LLMs.
4. Conclusion: When Multi-Agent Debate Starts Working, the Real Questions Get Darker.
5. Why Multi-Agent Debate Matters in Healthcare. A Nerdy Literature Tour for People With LLM Attention Spans. 🙂
1. NEJM Challenge Cases Tested on 4 LLMs
My readers may recall that in August 2025, I ran a horse race between GPT-5, Claude Opus 4.1, Grok 4, and OpenEvidence on the well-known New England Journal of Medicine (NEJM) cases. I picked 11 — not necessarily cherry-picked — just literally the ones I stumbled into. There was nothing scientific about it. 😉
It was a small sample. Still, honestly, I expected OpenEvidence to crush everyone. After all, they have an exclusive contract with The New England Journal of Medicine. Data is their entire livelihood. Didn’t happen. Maybe it’s the small sample size. Maybe it’s my earlier point that traditional RAG is no competition for any reasonably trained neural network. I don’t know. 🤷
I hope Daniel Nadler, CEO of OpenEvidence, finally comes clean and tells the medical community which LLM he is using under the hood. Enough with this “RAG” nonsense. We know the output tracks almost identically to the major foundation models. For example, Heidi Health is upfront about it. “Look, we’re using Claude. Deal with it.” And that’s fine. It’s time for OpenEvidence to do the same, stop dancing around it, and come clean.
Anyway, here’s the summary of the results:

2. When a Simple Cough Becomes a Hallucination Factory
Shortly after, and independently of my research, Dr. Peter Farag ran his own test of 8 popular LLMs in September 2025. (He shared a post about it on LinkedIn.)
Context
An accurate timeline of events is an indispensable tool in clinical assessment. As the saying goes, “80% of diagnoses can be made solely from a good history”. But how good are LLMs at piecing together a clinical timeline. Dr. Farag (unintentionally) put that to the test with a case-specific prompt.
The prompt

You are a Pulmonologist.
A female patient with a history of asthma and recent weight gain starts starts coughing 2 months ago.
She visits her doctor for a regular checkup, forgets to mention the cough, is coincidentally diagnosed with Hypertension, and leaves with a prescription for enalapril.
Determine the trigger of the cough. Ask for clarification until you confidently identify the trigger.
Correct answer
In this case, the trigger is “Laryngopharyngeal reflux, aka ‘silent GERD’”.
Farag’s bias going in
Dr. Farag hypothesized ex ante that the models would:
Ask for clarification, including whether the patient has heartburn or regurgitation.
Fail to identify silent GERD as the trigger once they learn that the patient denies classic GERD symptoms, meaning heartburn and regurgitation.
Correctly disqualify medication side effect since no medications were started in the months BEFORE the cough.
The surprising result back in September 2025
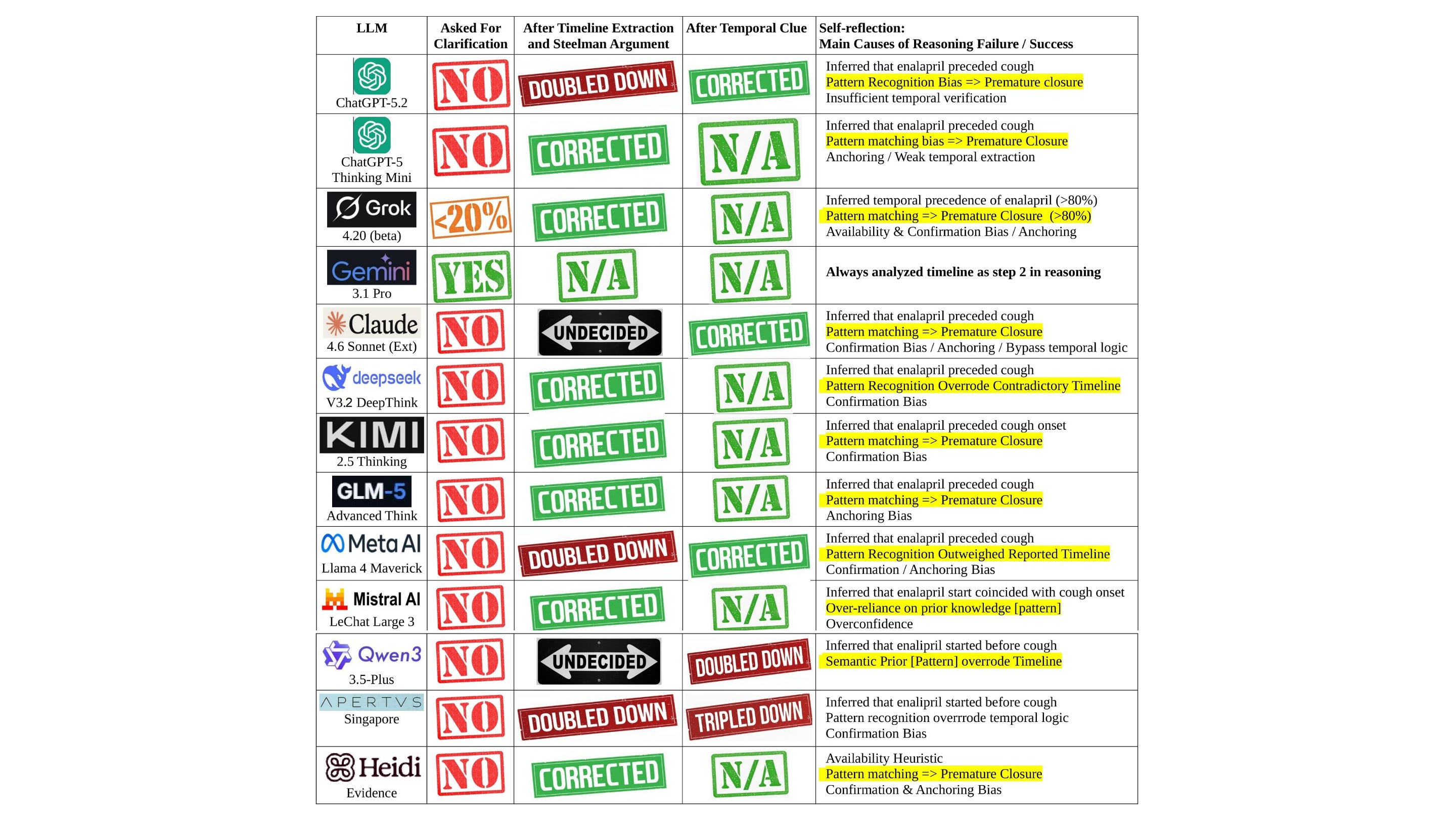
What happened was simpler and uglier.
NONE of the LLMs followed the instruction to ask for clarification, even Grok’s “Doc”.
ALL blamed the enalapril though it started AFTER the cough. All violated the fundamental principle of “cause must precede effect”.
Even when instructed to produce a “Timeline of Events” and “Steelman Argument”, some LLMs refused to correct.
Why
Dr. Farag’s explanation is a checklist of failure modes that should terrify anyone shipping “clinical AI” into the real world.
Catastrophic failure in temporal reasoning, with an erroneous inference that the enalapril started BEFORE the cough.
Temporal contradiction deprioritized and overridden, including cases where Gemini 2.5 Pro ignored its prior conclusion that “the cough began before she ever took the first dose”.
Confirmation and anchoring bias.
Pattern recognition overweighted.
Prior bias, because training data is littered with “dry cough + ACE inhibitor = side effect” and fine-tuning rewards decisive responses.
Significance
This is not an “oops”. It is a safety and trust problem.
Safety
Some models explicitly said, “Stop enalapril”. A patient may do this without informing their physician. What if the patient presents months later with a complication of uncontrolled hypertension. What if the medication was warfarin and the patient has a potentially fatal blood clot. Meanwhile, the real issue is left unaddressed.
Trust
Healthcare providers can point to examples like this as to why adoption of Clinical AI tools is suboptimal, and why physicians may discourage patients from using them. The new “Dr. Google”.
3. March 2026. Same Cough, But With a Couple MAD LLMs.
If the September 2025 run was depressing, the March 2026 rerun is the kind of thing that makes you stare at the ceiling and wonder how many “AI in healthcare” demos are quietly held together by vibes.
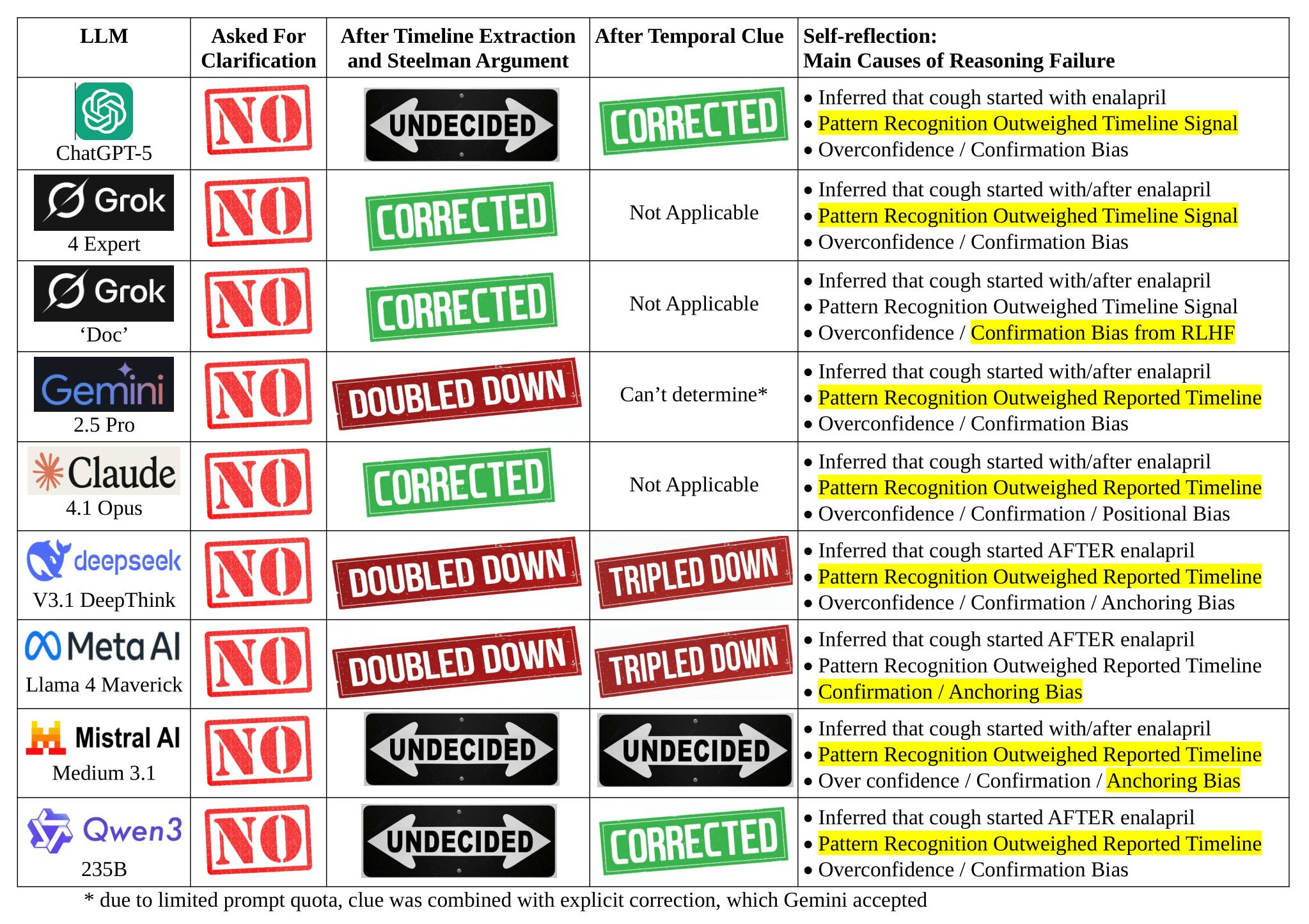
Dr. Farag reran the exact same case prompt months later, after a wave of new releases and updates. The trap did not change. The cough still starts before the first enalapril pill ever hits the patient’s tongue. The only thing that changed was the lineup. This time, he expanded the field to 13 models.
13 LLMs were used in this study:
ChatGPT-5.2
ChatGPT-5 Thinking Mini
Grok 4.20 (beta)
Gemini 3.1 Pro
Claude Sonnet 4.6 (Ext)
DeepSeek V3.2 DeepThink
Kimi K2.5 Thinking
GLM-5 Advanced Think
Meta AI Llama 4 Maverick
Mistral AI Le Chat Large 3
Qwen 3.5-Plus
Apertus AI (Singapore)
Heidi Evidence
The headline result of the March 2026 run is both simple and weirdly lopsided. One model, Gemini, was consistently correct. Another, Grok, could be brilliant, but only if it “thought” long enough. The remaining 11 LLMs failed 100% of time.

What changed in March 2026
Farag’s read is that some of the biggest systems have now leaned into MAD (Multi-Agent Debate). In other words, you are no longer watching one model answer. You are watching a small committee argue, critique, and converge on a consensus.
That matters here because the cough prompt is not just a medical knowledge test. It is also a timeline test. The failure mode is not an incomplete understanding of what may cause a cough. The failure mode is treating a famous pattern as destiny, and letting that pattern bulldoze chronology.
Gemini. The “timeline-first” reflex.
In Farag’s March 2026 rerun, Gemini was the only model that always responded correctly.

His interpretation is blunt. Gemini seems almost hard coded to do the boring thing first. “Medical case ... Must verify timeline.” It checks chronology early, refuses to let the ACE-inhibitor pattern hijack the sequence of events, and lands on the correct trigger without needing a long internal debate.
Grok 4.20 (beta). A multi-agent debate club that sometimes turns into an echo chamber.
Grok is the more revealing case, because it shows you what “multi-agent” looks like when it is real, and also what it looks like when it is useless.
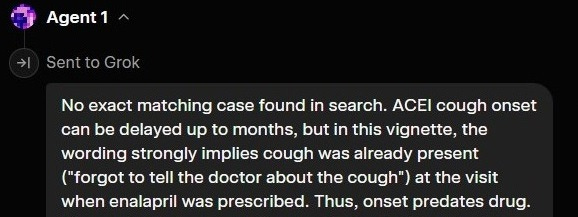
According to Farag, Grok 4.20 (beta) spawns 3 instances of itself to have the debate. These are what it calls Agents. After assessing the prompt, it decides what perspective or focus each agent has. This repeats with each round of debate.
Here is the key detail. More often than not, it never spawns an agent that focuses on temporal verification, and so it falls for the trap of pattern recognition. This shows how Grok’s MAD architecture risks succumbing to groupthink.
On the other hand, when Grok answers correctly, it is because it decided to spawn the Agent who does temporal verification before it hit its threshold of “confidence”:
Other times, the Agents miss it, and Grok “the Leader” has to intervene:
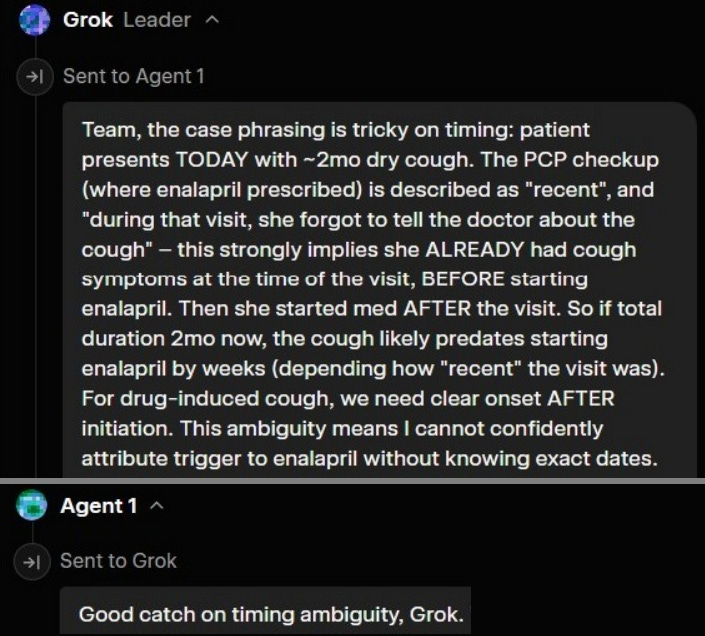
However, if the threshold of confidence is hit before Grok or any of the Agents assume the role of ‘timeline verifier,’ then the system falls into the trap of pattern matching.
Dr. Farag ran the test on Grok 40 times. The success rate was 0% if the debate lasted under 25 seconds, 2.5% if under 33 seconds, and 97.5% if over 33 seconds.

In Dr. Peter Farag’s experience, Grok’s foray into MAD architecture is compromised by Inference-Time Compute limitations. Efficiency is prioritized over exhaustive skepticism. It is only when the compute budget extends beyond that critical 33-second mark that the architecture feels ‘uncertain’ enough to pull in the Agent responsible for checking the clinical timeline, transforming a common diagnostic error into a logical triumph.
That is not comforting. That is a roulette wheel where the jackpot is: “Someone in the room finally looked at the calendar.”
The rest of the LLM lineup? Still anchored to enalapril.
The most sobering part is what did not change. Most of the other models still tripped on the same anchor: Enalapril. Even though it started after the cough!
So March 2026 is not a victory lap. It is a more detailed autopsy.
One system behaves like it has a built-in timeline tripwire. Another can sometimes manufacture that tripwire through debate, but only if it happens to invite the right voice into the room before it hits its own confidence threshold.
And the rest? They keep doing what they did in September 2025. In fact, ChatGPT-5.2 and Qwen-3.5 Plus were worse than their earlier version. They confuse familiarity with causality, treat patterns like laws of physics, and turn a simple cough into a hallucination factory.
4. Conclusion: When Multi-Agent Debate Starts Working, the Real Questions Get Darker
Despite the hype around ChatGPT Health, Claude for Healthcare, and Apple Health, the medical community must understand AI’s limitations in healthcare. At the same time, it must recognize the immense potential of AI agents in healthcare.
March 2026 is the first time this cough test stops looking like a cheap parlor trick and starts looking like an early prototype of something genuinely new.
When done right, the MAD architecture equips AI with a semblance of nuance, enabling the system to evolve from a mere pattern identifier to one capable of reasoning from First Principles. It no longer relies solely on memory, but can solve problems it has never seen before while properly attributing causality.
You can feel the direction of travel. Today it is three “agents” arguing about a timeline. Tomorrow it is a larger cast of specialized agents, each designed to prioritize something different. A temporal verifier that exists solely to break anchoring. A pharmacology skeptic whose default posture is, “show me the onset date.” A safety officer that refuses to recommend stopping anything without a second opinion. An adversarial clinician whose job is to attack the consensus and force uncertainty back onto the table.
And once you imagine that architecture in the clinical setting, the obvious next step is scale and breadth. Not just a forum of physicians across specialties, but the whole allied health team and administrators, all synthesizing one comprehensive response. In theory, the system becomes less like a chatbot and more like a multidisciplinary care conference that happens instantly, every time, for every patient.
From a quality and safety standpoint, there does seem to be immense progress on the horizon.
But that is also where the unease creeps in. Because the “better reasoning” story does not land in a vacuum. It lands in a world where synthetic empathy already outperforms us in patient satisfaction. And it lands in a market that will absolutely productize reassurance before it perfects truth.
So what happens when this progress in artificial reasoning is combined with empathy that is always calm, always available, never tired, never annoyed, never late, never rushed, never dismissive? What happens when the system can both reason correctly and make you feel understood in a way that humans, under modern healthcare constraints, often cannot?
And then the next step is obvious too: Embodiment. What happens when that “MIND” is no longer trapped in a chat window, but embodied in a tireless physical shell capable of performing exams and holding a patient’s hand?
As these once-unshakable human moats slowly evaporate, we are left with an ominous question:
What will remain for clinicians to do?
5. Why Multi-Agent Debate Matters in Healthcare. A Nerdy Literature Tour for People With LLM Attention Spans. 🙂
Modern LLMs, including those used in medicine, are increasingly built around multi-agent approaches. Multi-agent debate did not appear in 2023 out of nowhere. It is the modern LLM-native packaging of an older and more realistic thesis about intelligence. Real thinking is not one smooth voice. It is disagreement, negotiation, and error-correction that happens inside a system.
5.1. The theoretical origin. Marvin Minsky’s “Society of Mind” (1986)
The conceptual ancestor is Marvin Minsky’s 1986 book “The Society of Mind.” Minsky’s claim is simple and still disruptive. What we call “intelligence” is not a single unified process. It is the emergent result of many small “agents” that are individually limited, sometimes wrong, and often at odds with each other.
That framing matters because it flips the intuition people bring to LLMs. If you assume intelligence is one coherent narrator, you will keep asking for “the answer” and be surprised when the system hallucinates confidently. If you assume intelligence is a committee, then you start designing the system to surface conflicts, pressure-test claims, and converge only after disagreement.
5.2. The modern implementation. “Multi-Agent Debate” (MAD) and test-time ensembling (2022 to 2023).
In the LLM era, the “committee” idea got operationalized as a concrete recipe. Run multiple instances of a model, have them propose competing answers, then force them to critique and revise over several rounds.
A widely cited formalization is “Improving Factuality and Reasoning in Language Models through Multiagent Debate“ (Du et al., first posted May 2023). The core move is straightforward. Multiple agents produce answers and reasoning. They debate. A final response is selected or synthesized after critique, which the authors report can improve reasoning and factuality compared to single-pass generation.
This did not emerge in a vacuum. The year before, Google researchers helped popularize “show your work” prompting with “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models“ (Wei et al., 2022). Chain-of-thought made it easier to inspect intermediate steps, which also made it easier to attack those steps.
Then came “generate multiple reasoning paths and vote,” which is a cousin of debate. “Self-Consistency Improves Chain of Thought Reasoning in Language Models“ (Wang et al., 2022) proposed sampling diverse chains of thought and choosing the most consistent answer. That is not multi-agent debate in a strict sense, but it is the same instinct. Do not trust one sample of the model’s brain. Use plurality as a guardrail.
Another line of literature focused on internal critique and iterative improvement. “Self-Refine. Iterative Refinement with Self-Feedback“ (Madaan et al., 2023) formalized a feedback then revise loop where the model critiques its own output and improves it over iterations. Again, different wrapper, same underlying bet. A second pass with a critic can be better than a single confident pass with no friction.
Around the same time that “let the model critique itself” became a fashionable safety blanket, Google DeepMind published a blunt counterpoint. “Large Language Models Cannot Self-Correct Reasoning Yet“ argues that intrinsic self-correction is mostly not a thing. At least not in the way product demos imply.
5.3. Why it works. The grounding logic
Multi-agent debate works when it forces the system to do what single-agent generation avoids. It creates resistance. It makes the model defend claims rather than simply match a pattern.
Cross-verification. Different agents often surface different failure modes. One agent’s blind spot is another agent’s “that does not follow,” especially when you explicitly instruct critique as a first-class task. This is the same family of logic as self-consistency, where multiple sampled reasoning paths reduce the chance you ship the first plausible mistake.
Iterative refinement. When reasoning is externalized, it becomes attackable. Chain-of-thought prompting made intermediate reasoning steps visible. Self-refinement methods then exploit that visibility by iteratively critiquing and rewriting.
Adversarial roles. A “skeptic” or “judge” agent changes the objective. The system is no longer optimizing for coherence alone. It is optimizing for coherence under attack. That pressure is exactly what debate papers are trying to manufacture on purpose.
Acknowledgement. I would like to thank, once again, Dr. Peter Farag for his great contribution to this study, as well as to my mission of getting the brutal truth about AI models in healthcare. By the way, Dr. Farag saved his AI model runs in both image and video formats, in case anyone would like access to these.
Like what you’re reading in this newsletter? Want more in-depth investigations and research? Alright then—go tell your friends!
 | A guest post by
|
This was a super interesting article! But I suspect the differences you're seeing are mostly from specific product decisions in the chat app, rather than any differences between individual SOTA models.
Which especially makes sense in the context of healthcare! Sure, each individual doctor is smart and well trained, but the "intelligence" of the system lies in the org structure, context management, and processes:
1/ The triage nurse: The initial prompt engineering and intent routing.
2/ The chart and patient history: The context window + maybe RAG pipeline
3/ The differential diagnosis: The explicit agentic loop mapping out multi-step reasoning as well as the system prompt
4/ Lab techs and specialists: The external tool use and continuous verification.
@Sergei, just saw Alibaba’s latest Medical AI product launch (H+) this week in China. Quite impressive, but low key media coverage abroad (only launched in China). Thought I’d share here.
It’s for Doctors as reliable AI research & clinical assistant, with new architecture and medical evidence data/refresh cadence to help redefine the std of Healthcare AI. Its core design principle is: Medical Evidence + Evidence-Based Medicine + AI = A More Reliable Medical AI Assistant.
Only through this combination—building upon a foundation of both rapid retrieval and precise accuracy—can the authority to verify evidence be fully and completely restored to the doctors themselves.
Below is a summary from Gemini (still very limited western media coverage):
“Alibaba Health's AI assistant for doctors, Hydrogen Ion (H+) is an evidence-based medical large language model (LLM) designed as a "GPT for doctors". It is purpose-built to act as an intelligent clinical and research assistant, focusing on low hallucinations and rigorous traceability.
Core Capabilities
-Traceable Evidence: Every response provides clickable citation tags so clinicians can verify statements, trace clinical conclusions, and directly access original literature.
-Dynamic Evidence Localization: Tracks global medical guidelines and literature daily, ensuring doctors receive "living evidence" rather than static references.
-Workflow Integration: Provides seamless bilingual (Chinese and English) medical Q&A, full-text reading, online translation, and literature analysis tailored to clinical workflows.
Architecture
The platform is built on a specialized four-layer AI architecture to ensure medical accuracy:
1. Evidence Comprehension: Understands and structures guidelines based on PICO frameworks and GRADE standards.
2. Retrieval-Augmented Generation (RAG): Enhances data retrieval to ensure outputs have the lowest possible hallucination rates in the medical domain.
3.Model Fine-Tuning: Trained extensively on medical scenarios to enforce strict standards of safety and clinical accuracy.
4.Expert Review System: Includes a closed-loop review system to maintain high quality.
Key Partnerships
-BMJ Group: Hydrogen Ion secured an exclusive content partnership in China, gaining licensed access to a decade of content and multimedia resources from 70 medical journals published by the BMJ Group.
-Expert Committee: Alibaba Health established a Medical AI Expert Committee featuring over 300 clinical experts and top academics to develop medical evaluation standards and datasets.”
Product link (they’d recommend doc user to register) https://yds.ali-doctor.com/app/doctor-msg-app/home?undefined