

What's Actually Under the Hood of OpenEvidence's AI
The best educated guess at how OpenEvidence's AI likely works.

Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
Important Disclosure. This publication is written and distributed by an independent journalist. It is protected by the First Amendment to the U.S. Constitution and related principles of free expression. Those protections do not relieve me of the obligation to report accurately, and I take that obligation seriously. I strive to rely on verifiable facts, primary-source documentation, and other evidentiary material concerning companies and individuals. Disagreements over interpretation, opinion, tone, or editorial framing are not the same as factual errors. I stand by my reporting, my research, and my sources absent a demonstrated and material factual mistake. I have no financial interest, whether long or short, in any of the companies mentioned in this article.
Some clinicians I’ve talked to love OpenEvidence. Others, let’s just say, are skeptical. But most would agree that it is one of the hottest companies in healthtech right now.
One of the clinicians with the most positive views is my colleague Christian Pean MD, MS, who just published a fascinating piece on the various use cases of OpenEvidence.
So, logically, to keep things interesting, let me take the skeptical view on OpenEvidence. 😉 Or, as some might call it, the realistic view.
But first, I want to take a moment to thank all of my supporters. I’m often very critical of certain things happening in AI and healthcare. But I promise you, it’s only because I genuinely care and want to make things better for all of us. So, thank you for your understanding.
I receive a lot of messages daily, and I always respond promptly to every one of them. Most are incredibly kind and supportive.

I want to highlight one recent message in particular. A student reached out recently asking for full, paywall-free access to my Substack. Of course, I granted it, as I always do.
This brings me to another important message. If you cannot afford this article—perhaps you’re a student or currently between jobs—please reach out. That’s precisely why I created the AI Health Uncut Founding Member Club, currently at 17 and counting. Thanks to generous donations and support from these wonderful individuals, I’m able to provide access to anyone who needs it. By the way, students reach out frequently, and I’m always glad to help.
If you’d like to support my mission to uncover the brutal truth in healthtech and healthcare AI, please consider becoming a Founding Member of the AI Health Uncut community. You can join through this link. You’ll be making a real impact, helping me continue to challenge the system and push for better outcomes in healthcare through AI, technology, policy, and beyond.
🚨 A quick announcement:
I’d like to highlight a couple of events where I’ll be speaking.
First, if you’re not at NY Tech Week this week, where are you? 😉 Definitely come to the Health2Tech event on Thursday, June 4, which is on the NY Tech Week calendar. I’ll be on a panel discussing the most important healthtech events of the month as part of the Digital Health Inside Out Vitals podcast. I’ll be speaking alongside my co-hosts, Alex Koshykov and Stephanie Davis.

Then, after three years of investigating bad actors in healthtech, I’ll be sharing what I’ve learned in a talk called “How to Spot the Next Theranos in Healthcare AI.” I’ll be speaking at the Digital Health & AI Innovation Summit in Boston on June 9.
If you can make it to either event, I’d be very happy to meet you.
OK. Back to OpenEvidence…
We don’t know much about OpenEvidence’s AI. The company has been super secretive about it. But by now there are a lot of clues.
This “back of the envelope” calculation that I present here came from discussions with some very smart people. (I therefore take very little credit.) In particular, the bulk of this paper I attribute to someone who prefers to be called “anonymous-but-always correct” author. 😉
So here goes Satoshi Nakamoto 2.0. 😉
In Part 1, I walked through the Evidence-Based Medical AI market, the OpenEvidence / Doximity legal saga, the talent raids, the copycat pattern, and the money. I also gave you a preview of the architecture argument and promised I’d come back and do it properly. This is me keeping that promise.
Fair warning: this one gets a little technical. That’s the whole point. Because every confident claim OpenEvidence’s backers make about this product — “no hallucinations,” “it just won’t answer if the evidence is inconclusive,” “an ensemble of specialized models” — is a claim about architecture. And architecture is checkable. Not perfectly, not from the outside, but enough. Enough to separate signal from noise. And in this case, patients’ lives are on the line, so I think it’s worth the effort.
TL;DR:
1. What we actually know — and what OpenEvidence won’t tell us
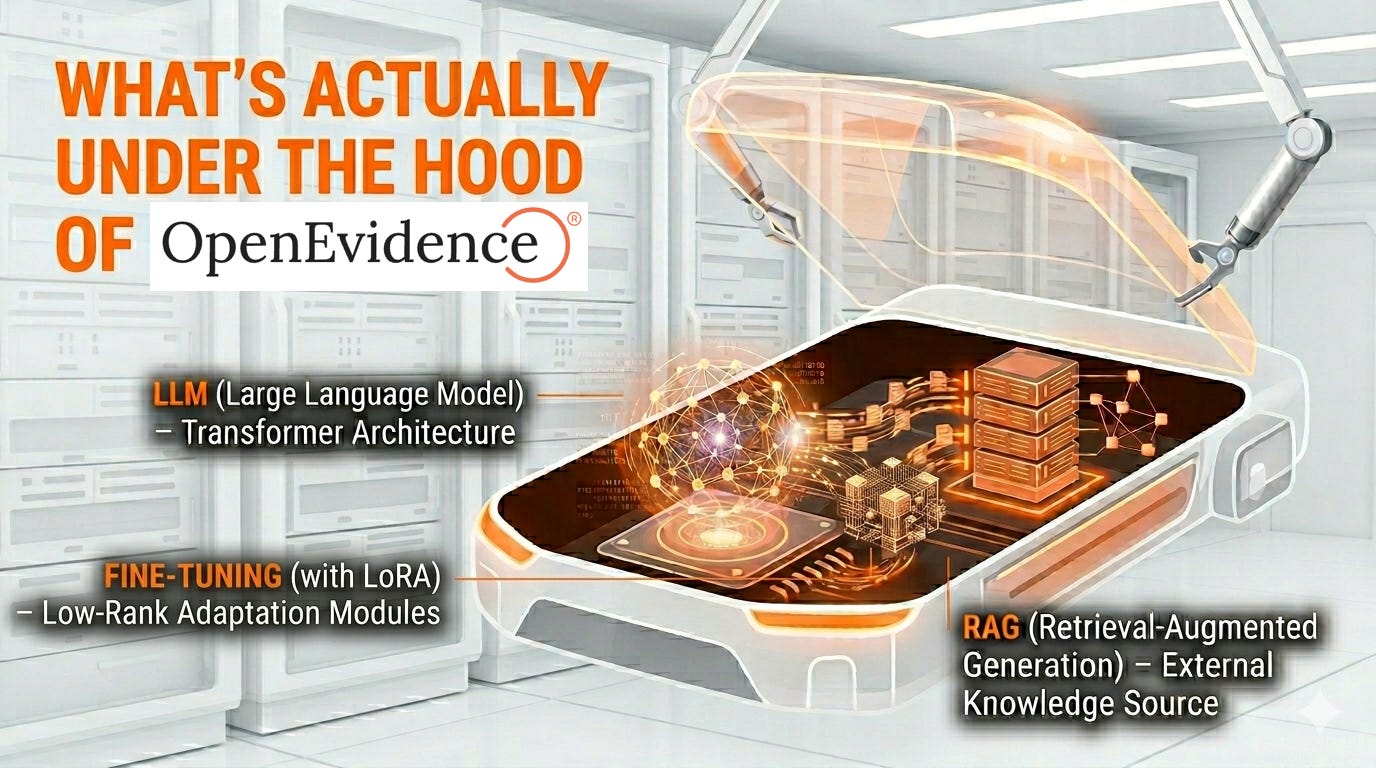
2. The base model: a frontier LLM in a lab coat
3. The fine-tuning: LoRA adapters, almost certainly
4. The RAG: 35 million papers and a reranker
5. The “no hallucinations” claim, and why it’s architecturally impossible
6. If “I don’t know” exists, here are the only four places it can live
7. The vaccines-and-autism tell: hard-coded refusal, dressed up as humility
8. The benchmark mess: the “perfect USMLE” mirage meets reality
9. Where this leaves us: nine open questions about OpenEvidence’s AI
10. Conclusion: OpenEvidence is a retrieval-summarizer with a marketing department
Alright, let’s open the hood on OpenEvidence’s AI:
