

OpenEvidence Goes Hippocratic AI
Healthtech has billions in VC money and the communication strategy of an 8-year-old caught lying


Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
Important Disclosure. This publication is written and distributed by an independent journalist. It is protected by the First Amendment to the U.S. Constitution and related principles of free expression. Those protections do not relieve me of the obligation to report accurately, and I take that obligation seriously. I strive to rely on verifiable facts, primary-source documentation, and other evidentiary material concerning companies and individuals. Disagreements over interpretation, opinion, tone, or editorial framing are not the same as factual errors. I stand by my reporting, my research, and my sources absent a demonstrated and material factual mistake. I have no financial interest, whether long or short, in any of the companies mentioned in this article. This article is for informational and opinion purposes only and should not be construed as financial or investment advice.
TL;DR:
A new peer-reviewed Nature Medicine study found that general-purpose frontier models (GPT-5.2, Gemini 3.1 Pro, Claude Opus 4.6) beat the specialized clinical tools OpenEvidence and UpToDate Expert AI on all three benchmarks they used. On real physician queries, OpenEvidence tied with Google’s free AI Overview.
Instead of a Letter to the Editor or a rebuttal paper, OpenEvidence ran a combative Twitter thread alleging contamination, “misrepresented metrics,” and an undisclosed conflict of interest. The reaction from clinicians was brutal.
Some of OpenEvidence’s technical criticisms are fair. I’ve made similar ones myself, here and here. MedQA and HealthBench both have real problems, and the authors actually concede most of them in the paper.
None of that is the real story. The real story is the asymmetry: this paper survived Nature Medicine peer review with public code and disclosed conflicts. OpenEvidence has zero peer-reviewed publications, no white paper, and a closed API it refused to give the authors. A company with no published evidence is lecturing a peer-reviewed paper about “rigor.”
And the reason it stings: OpenEvidence fine-tunes undisclosed open-source models served on rented infrastructure. That same stack is available to any well-funded competitor, so the paper squeezes their moat from above while the architecture commoditizes it from below.
I’ve reached out to OpenEvidence for some of the explanations of their AI system, including via a general company email and a personal DM to the founder and CEO, Daniel Nadler. As of this writing, I received no response.
But first, I want to take a moment to thank all of my supporters. I’m often very critical of certain things happening in AI and healthcare. But I promise you, it’s only because I genuinely care and want to make things better for all of us. So, thank you for your understanding.
I receive a lot of messages daily, and I always strive to respond promptly to every one of them. Most are incredibly kind and supportive.

I want to highlight one recent message in particular. A student reached out recently asking for full, paywall-free access to my Substack. Of course, I granted it, as I always do.
This brings me to another important message. If you cannot afford this article—perhaps you’re a student or currently between jobs—please reach out. That’s precisely why I created the AI Health Uncut Founding Member Club, currently at 17 and counting. Thanks to generous donations and support from these wonderful individuals, I’m able to provide access to anyone who needs it. By the way, students reach out frequently, and I’m always glad to help.
If you’d like to support my mission to uncover the brutal truth in healthtech and healthcare AI, please consider becoming a Founding Member of the AI Health Uncut community. You can join through this link. You’ll be making a real impact, helping me continue to challenge the system and push for better outcomes in healthcare through AI, technology, policy, and beyond.
OK, back to OpenEvidence going full Hippocratic AI…
OpenEvidence’s hectic and bizarre social media response to a peer-reviewed study showed weakness in my opinion. So they “went Hippocratic AI.”
As you may recall, Hippocratic AI ran a public humiliation and intimidation campaign against me a few weeks ago, after my exposé of the company. OpenEvidence’s playbook this past week rhymes with it. Different company, same instinct: when a critic lands a punch, swing wildly in public and hope the noise reads as confidence.
Communication and marketing departments of these companies seem to think any publicity is good publicity. Time will tell. But what I’m hearing from experts, clients, and partners is that this was a total PR blunder.
As I said, time will tell. We may find out the results of these PR campaigns sooner rather than later.
When a company responds to criticism with unusually aggressive public attacks or visible overreaction, it can raise fair questions about what may be happening behind the scenes. At the minimum, communication and marketing departments here have absolutely no idea how to read the room. Or they may simply be following orders from the management.
In this article, I’ll walk you through what actually happened. First, the Nature Medicine paper itself, and how badly OpenEvidence lost. Then OpenEvidence’s response, the twittorial that set healthcare Twitter on fire. Then the part where I do something their PR team can’t, and lay out where I actually agree with OpenEvidence. Then the asymmetry nobody at OpenEvidence wants to discuss, and why this paper hit a nerve in the first place, before I close on the bigger picture for the rest of the industry.
The Nature Medicine paper: frontier LLMs outperform specialized medical AI
On June 12, 2026, Nature Medicine published a Brief Communication article with a title that does not leave a lot of room for interpretation: “General-purpose large language models outperform specialized clinical AI tools on medical benchmarks.”

The team is led out of NYU Langone, with Krithik Vishwanath and Eric Oermann as corresponding authors. The setup is simple and, frankly, the kind of thing someone should have done two years year ago. (I explain why two years at the end of this section.)
They put two specialized clinical AI tools, OpenEvidence and UpToDate Expert AI, up against three frontier models: GPT-5.2, Gemini 3.1 Pro, and Claude Opus 4.6. Three stages:
500 MedQA questions (USMLE-style, multiple choice) for raw medical knowledge.
500 HealthBench items for alignment with expert clinicians.
The RCQ benchmark: 100 de-identified real physician queries pulled from NYU Langone’s HIPAA-compliant GPT instance, scored by 12 blinded US clinicians across four dimensions, producing 1,800 model–question annotations.
The result, in their own words:
Frontier LLMs outperformed the clinical tools on all three benchmarks.
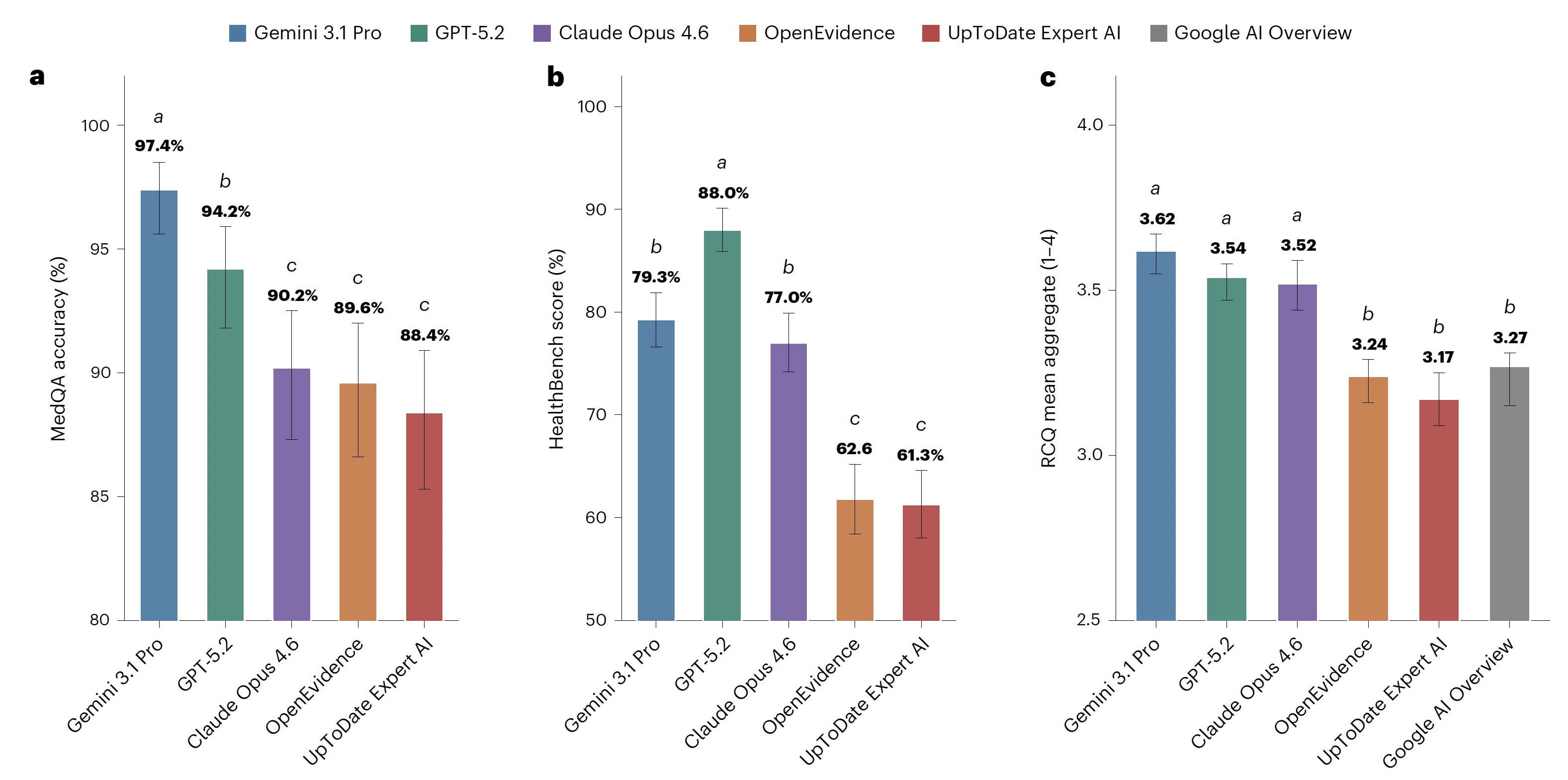
The numbers are as follows:
MedQA: Gemini 97.4%, GPT 94.2%, Claude 90.2%. OpenEvidence 89.6%, UpToDate 88.4%.
HealthBench: GPT 88.0%, Gemini 79.3%, Claude 77.0%, OpenEvidence 62.6%, UpToDate 61.3%.
RCQ: the frontier models cluster at 3.52 to 3.62 on the 1–4 scale. Google AI Overview (3.27), OpenEvidence (3.24), and UpToDate (3.17) sit in the lower tier together.
This last part may be counterintuitive, which is what makes the result so fascinating. The auto-enabled Google Search AI Overview, the thing that appears above your search results whether you asked for it or not, scored as well as or better than OpenEvidence and UpToDate across all dimensions of real clinical queries.
And the failure mode is specific. OpenEvidence scored lowest on clarity (mean 2.84). The paper notes its weakness was communication, not knowledge. The error taxonomy in the Extended Data is even less flattering: OpenEvidence racked up 52 flagged low-scoring responses, including 15 for incomplete clinical content, 13 disorganized, and 12 safety-critical omissions, more than any other model in the study.
To their credit, the authors are careful. Apart from the somewhat clickbait-y title, they are actually quite modest in the paper itself. They call this “a snapshot of a rapidly evolving landscape rather than a permanent ordering of approaches.” They flag that deeply subspecialized tasks may still favor domain-specific tuning. And they name their own primary evidence clearly: the blinded clinician evaluation on the RCQ, which is free from training contamination, is the part to trust. HealthBench is supplementary.

I warned about exactly this phenomenon on this platform in August 2024, almost two years ago, because it’s what I’d been watching in my own daily work: foundational general-purpose models quietly closing and then erasing the gap with fine-tuned, RAG-bolted clinical tools. In fact, I had been warning that specialized fine-tuning as a business moat may be disappearing. People, mostly outside of evidence-based AI, were laughing at me.
Nobody’s laughing now.
OpenEvidence’s response
Here’s where it gets interesting.
A company that (according to the Nature Medicine paper) just got outscored by Google’s free search widget had a few options. Submit a Letter to the Editor. Publish its own peer-reviewed rebuttal. Open up its API and let independent researchers benchmark it properly. Take the high ground.
Instead, OpenEvidence went entirely “Hippocratic AI” by running a “twittorial.”

The thread came out swinging. OpenEvidence made three points:
One, contamination. OpenEvidence argued that frontier models have simply seen MedQA and HealthBench questions during training, and posted screenshots of ChatGPT and Gemini happily identifying the exact source dataset of a benchmark question. It’s a real concern. I’ll come back to it.
Two, “misrepresented metrics.” They claimed HealthBench scores responses “largely based on arbitrary/subjective stylistic choices,” with an example of OpenEvidence losing points for not using a specific email header. Again, admittedly, there’s something here. I’ll come back to it too.
Three (and this is the one that made me sit up), peer-review records. OpenEvidence stated that “public peer review records indicate” the two “flawed datasets” were the only evaluations in the initial submission, and that after peer reviewers flagged that the results “lack[ed] epistemic grounding,” the RCQ dataset was “subsequently added.”
Then the heavy artillery: a top-of-thread post accusing the paper of a “massive undisclosed conflict of interest.” OpenEvidence claimed the study authors run a competing in-house medical AI, asked OpenEvidence for API access including rights to build a “competing product,” were declined, and that “then, this paper coincidentally appeared.”
They closed with a flourish: the paper and its benchmarks are “clearly ill-equipped to judge clinical decision support tools,” and you shouldn’t “boil the answer down to a contaminated multiple choice quiz.”
The reaction online was not what OpenEvidence hoped for.
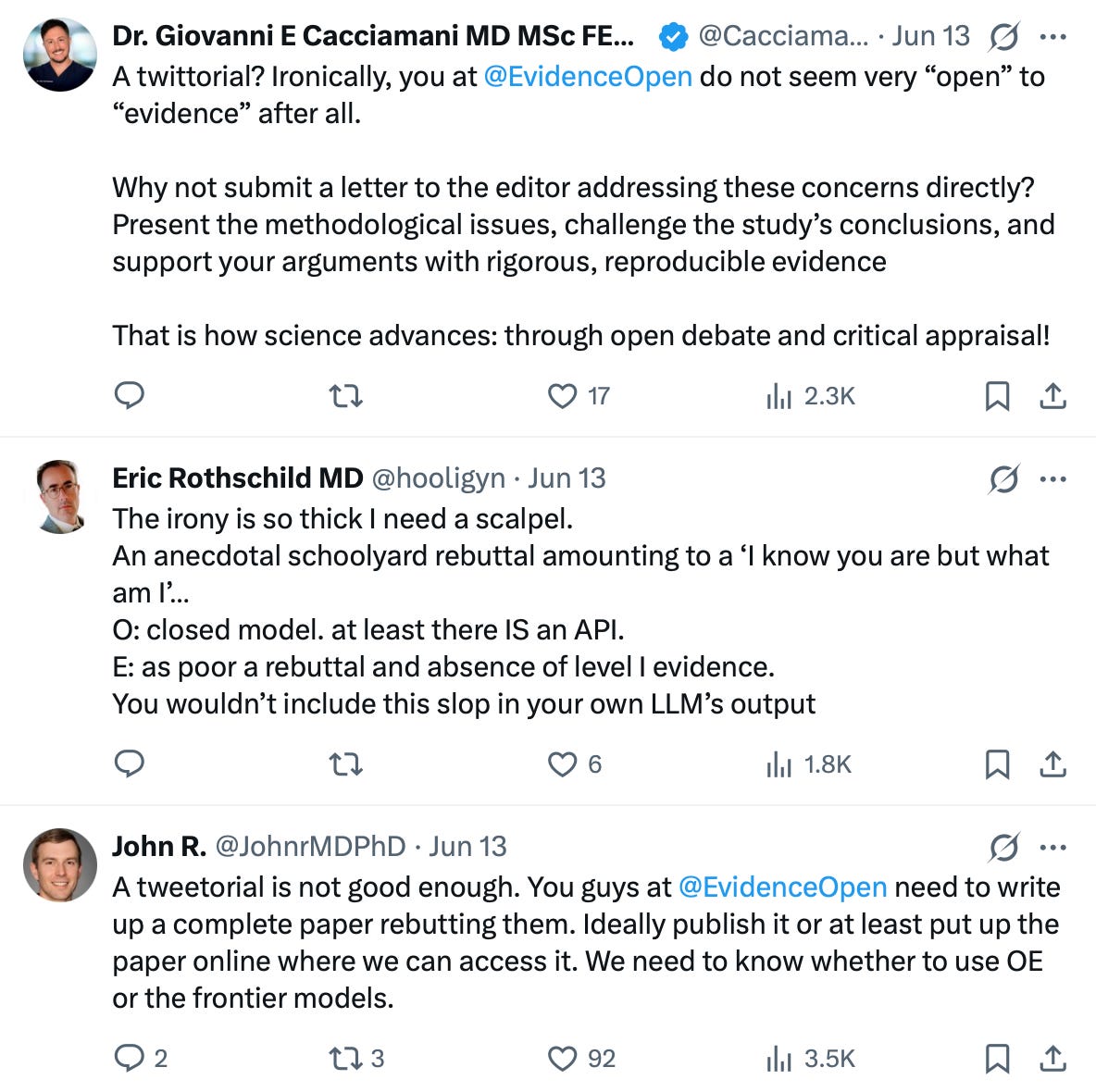
Giovanni Cacciamani, MD: “A twittorial? Ironically, you at @EvidenceOpen do not seem very ‘open’ to ‘evidence’ after all. Why not submit a letter to the editor?”
Eric Rothschild, MD: “The irony is so thick I need a scalpel. An anecdotal schoolyard rebuttal amounting to a ‘I know you are but what am I.’”
John R., MD, PhD: “A tweetorial is not good enough. You guys need to write up a complete paper rebutting them. Ideally publish it.”

Hayong Jung pointed out the obvious: “It’s hard to take [OpenEvidence’s] appeal to “rigorous evaluation” seriously when OpenEvidence makes independent evaluation so difficult,” with a closed API forcing researchers to scrape the system just to benchmark it.
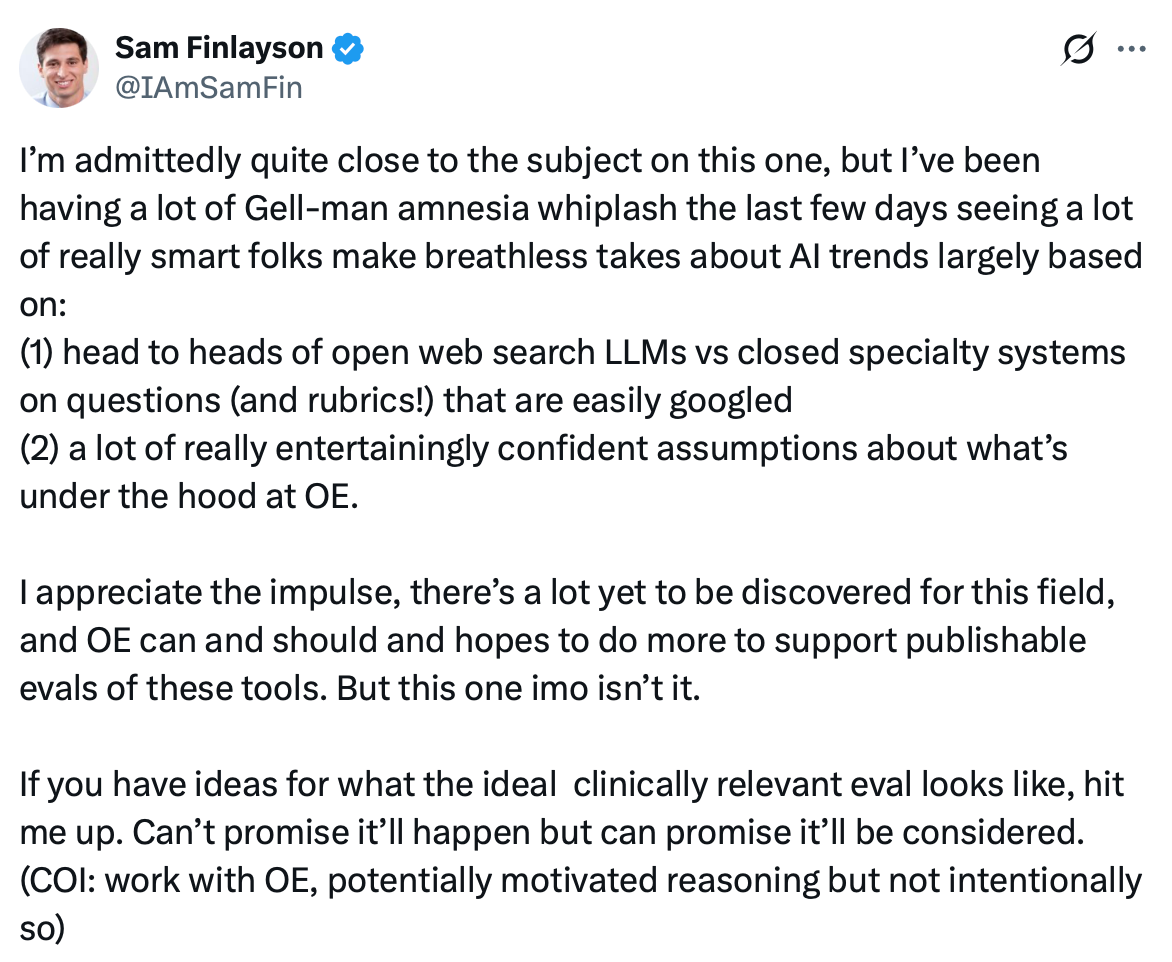
And then there was Sam Finlayson, MD, PhD, who works with OpenEvidence and disclosed it, complaining about “a lot of really entertainingly confident assumptions about what’s under the hood at OE.”

I’ll take at least partial credit for that one. I just did a deep dive called “What’s Actually Under the Hood of OpenEvidence’s AI.” So thank you for noticing my work. 😉
So I replied:

“Sam, with all due respect, we are all guessing what’s under the hood because @EvidenceOpen has not published a paper explaining what’s under the hood. Which is ironic, because ‘Open’ is right there in the name.”
Sam Finlayson’s complaint about “confident assumptions” is exactly the problem. We are all guessing, because OpenEvidence has given us nothing else to do.
Where I actually agree with OpenEvidence
Now I’m going to do something OpenEvidence’s PR team apparently can’t: concede a point.
But this part is personal, so I prefer to share it only with my paid subscribers. 😉
